왜 티스토리에서 운영하던 블로그를 독립서버에 구축한 워드프레스로 이사했는지는 이 포스트에서 언급하지 않겠다. (그 이유 보러가기)
이유야 어찌됐든 이사를 결심한 다음 가장 중요한 작업은 바로 티스토리 블로그에 작성돼있는 1,000개에 육박하는 포스트의 백업이었다. 다른 블로거가 공개한 파이썬 코드도 있고 티스토리에서 제공하는 백업 기능도 있지만 모두 사용하지 않기로 했다. 가장 큰 이유는 필요없는 html 태그와 어트리뷰트 그리고 스크립트가 잔뜩 포함된 상태로 백업이 생성되기 때문이기도 했고 img 태그의 이미지 파일 경로를 제대로 가져오지 못하는 문제가 있기도 했기 때문이다.
결국… 오랫만에 직접 코딩을 해야 했다. 오늘 이 포스트에서 완벽함과 거리는 멀겠지만 그 코드를 공개한다. 물론 이 코드가 모든 티스토리의 블로그에서 작동한다고 장담할 수는 없다. 스킨의 종류와 글쓴이가 포스트를 작성할 때 어떤 코드를 추가로 넣었는지 그리고 에디터의 종류와 상태에 따라 매우 다른 형태의 HTML 코드가 추가되어 포스트가 작성되기 때문이다.
Python의 BeautifulSoup의 사용
티스토리 블로그의 백업 코드를 파이썬으로 작성하면서 사용한 패키지는 BeautifulSoup 이라는 멋진 패키지다. 이 패키지는 웹페이지를 크롤링할 때 많이 사용하는 패키지인데 많은 개발자들이 여러 포스트에서 사용법을 공개하고 있기에 따로 설명을 올리지는 않는다.
흔히 bs4라 불리기도 하는 BeautifulSoup 패키지를 사용하면 Request 패키지를 통해 특정 URL의 HTML 페이지를 가져온 다음 HTML Parser를 통해 bs4 패키지의 객체로 포스트의 HTML Tag 객체를 찾기 또는 순차적인 접근을 통해 이동하면서 Tag 내부의 본문 또는 이미지 등 원하는 데이터를 추출해 낼 수 있다.
Request 객체와 BeautifulSoup 객체를 사용하여 티스토리의 포스트를백업하는 전체 소스는 아래 URL(GitHub)에 방문하여 참고하기 바란다.
https://github.com/taeho9/tistory-wp/blob/main/tistory_get.py
웹페이지를 Request 객체를 거쳐 BeautifulSoup 객체로 전달하기
웹페이지를 크롤링하려면 먼저 request 객체에 URL을 전달하며 URL 객체를 리턴받아야 한다. 그리고 그 URL 객체의 contents 속성을 다시 BeautifulSoup에 전달하여 HTML의 태그 파싱이 가능한 BeautifulSoup 객체를 생성해야 한다.
url = 'https://'+base_url+'/'+str(index)
try:
post = requests.get(url)
post.raise_for_status()
except requests.exceptions.HTTPError as e:
if post.status_code == 404:
print('◆◆◆ Post를 찾을 수 없습니다. https://' + base_url + "/" + str(index) + ' - 404 Not Found ◆◆◆')
time.sleep(3)
continue
else:
print('◆◆◆ 알 수 없는 예러가 발생앴습니다. https://' + base_url + "/" + str(index) + " ◆◆◆◆")
continue
page = BeautifulSoup(post.content, "html.parser")
이 코드는 base_url로 지정된 블로그 주소에서 index로 되어 있는 포스트를 Request 객체인 post에 가져온다.
그 다음 post가 404 Not Found 에러를 담고 있는 페이지가 아니라면 HTML Parser인 BeautifulSoup 객체인 page에 넘겨주는 코드다.
만약 블로그의 포스트 주소가 일련번호인 숫자가 아니라면 주소 문자열이 str(index)에 오도록 변경하면 된다.
포스트의 제목, 작성일, 슬러그 생성하기
다음 코드는 백업하는 포스트의 제목(title)과 카테고리(category) 그리고 작성일(wdate)을 추출하는 코드다.
# Get Title of article
title = page.find('title')
category = page.find('a', class_='jb-category-name')
wdate = page.find('li', class_='jb-article-information-date')
print('◆ Post No : ' + str(index) + ', Title : ' + title.text + " /" + str(index))
print('◆ Category : ' + category.text + ', Date : ' + wdate.text.strip())
print('◆ WordPress Slug : /' + str(index))
BeautifulSoup 객체인 page에서 find 메소드를 통해 원하는 데이터가 있는 태그를 찾아가면 된다. 제목은 title 태그(<title>)에 있고 카테고리는 a 태그(<a>) 중 ‘jb-category-name’ 이라는 클래스를 가진 <a> 태그에 있다. 마찬가지로 작성일(wdate)은 ‘jb-artical-information-date’에 있다.
다만 이 태그들과 class는 티스토리 블로그의 스킨에 따라 달라질 수 있다는 점을 기억해야 한다.
마지막으로 slug는 워드프레스에서 URL 중에서 포스트의 주소를 바꾸고 싶을 때 사용하는 기능이다. 필자의 블로그는 index 번호로 포스트의 주소가 되어 있어 str(index)를 slug로 생성했다.
블로그의 소스코드에서 포스트의 본문 찾기
다음은 필자의 티스토리 블로그의 포스트 뷰 화면에서 소스코드 보기(HTML 보기) 화면이다.
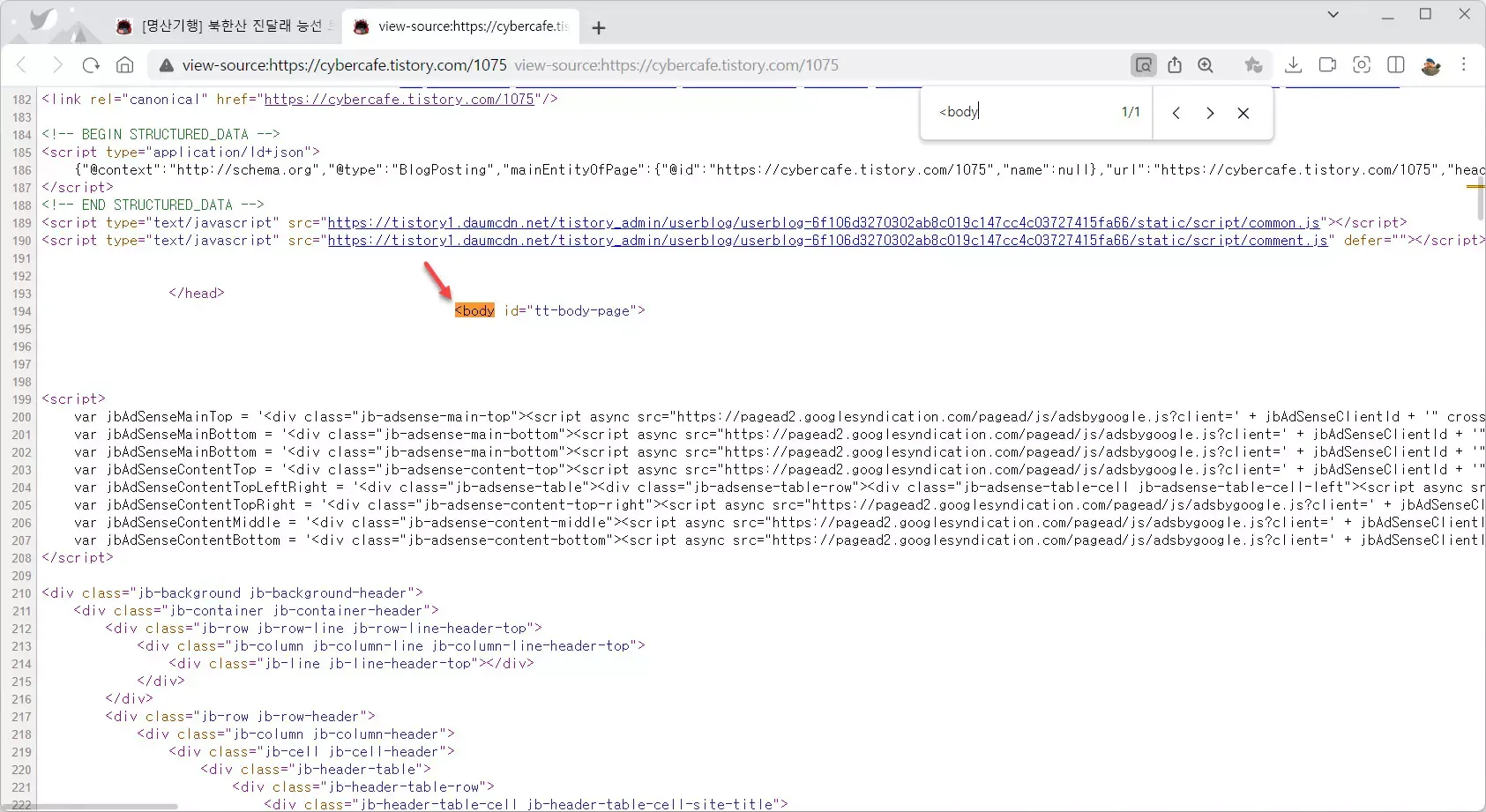
블로그에서 소스코드 보기 화면으로 들어가면 무려 194번째 라인에 <body> 태그가 보이는 것을 알 수 있다. 즉 블로그의 컨텐츠를 백업하는데 앞의 193 라인은 쓸모없는 HTML 코드라는 것이다. 하지만 티스토리의 백업 데이터를 살펴보면 이 193라인이 모두 들어있다. 사실 워드프레스로 블로그를 이사할 때 이 코드들은 모두 필요없다.
하지만 실제로 HTML을 분석해보면 실제 컨텐츠는 아래 화면처럼 더 아래로 내려가야 한다.
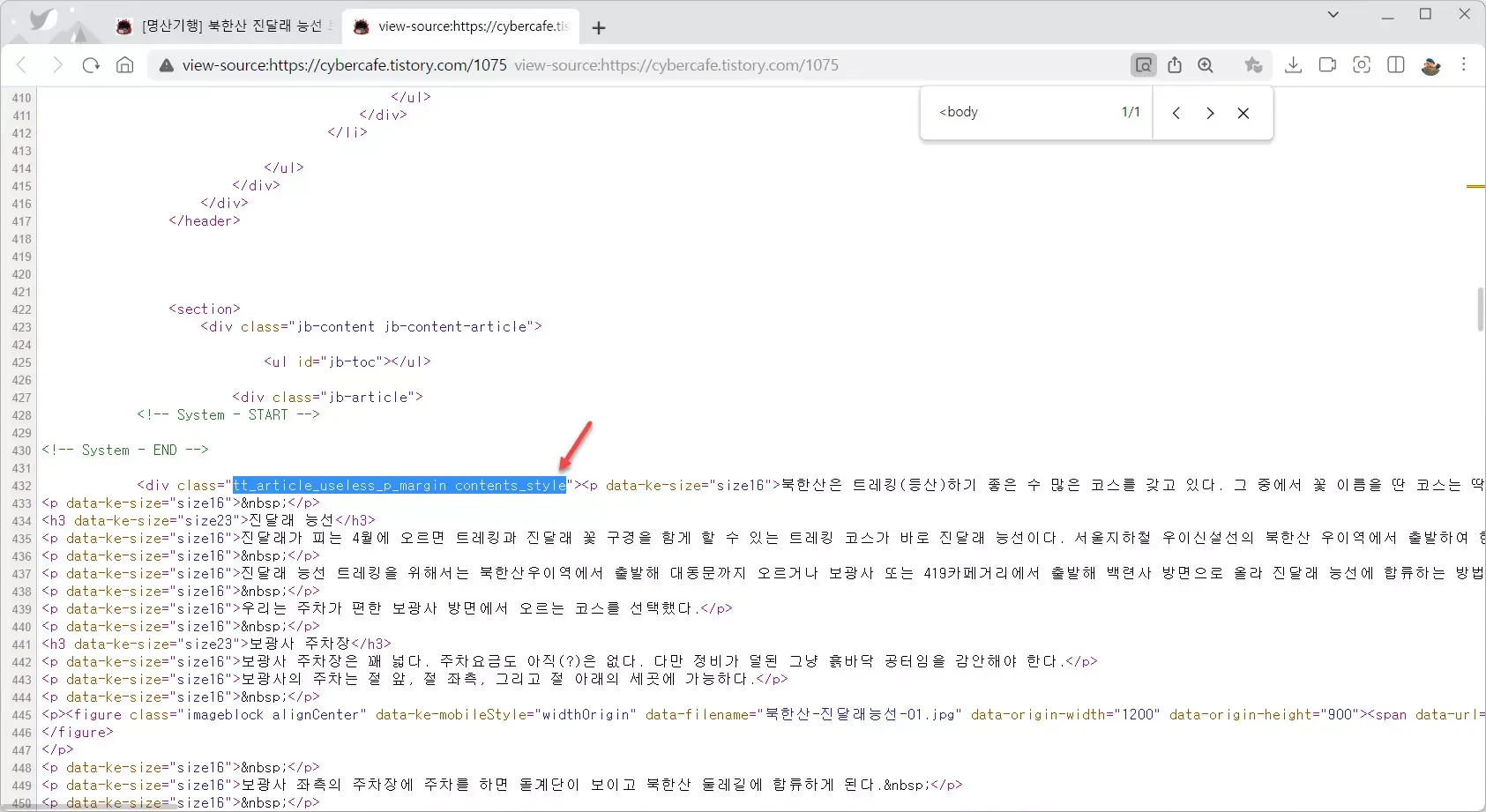
필자의 블로그에는 유료 스킨이 적용되어 있다. 그리고 이 스킨의 경우 HTML 소스코드에 수 없이 많이 등장하는 <div> 태그 중에서 class가 “tt_article_useless_p_margin contents_style”인 div 태그에 실제 컨텐츠가 포함되어 있었다.
즉 앞에서 BeautifulSoup() 에서 리턴받은 page 객체에서 find() 메소드로 div 태그 중 class가 “tt_article_useless_p_margin contents_style”인 태그로 이동한 다음 실제 백업을 시작하면 된다.
# 다운로드 이미지 파일과 새롭게 생성한 contents에 추가한태그의 카운트를 비교하기 위한 변수 초기화 img_file_count = 0 img_tag_count = 0 # Get Article : 지금까지 Post의 컨텐츠가 들어있는 3 종의 DIV 컨텐츠를 찾음. if (article := page.find('div', class_='tt_article_useless_p_margin')): print("◆ tt_article_useless_p_margin Class의 DIV 태그를 찾았습니다.") elif(article := page.find('div', class_='contents_style')): print("◆ contents_style class의 DIV 태그를 찾았습니다.") elif(article := page.find('div', class_=['tt_article_useless_p_margin','contents_style'])): print ("◆ 두 DIV 클래스를 모두 갖는 DIV 태그를 찾았습니다.") else: print("◆◆◆ Post의 컨텐츠를 담고 있는 DIV 태그를 찾을 수 없습니다. - Contents Div tag Not Found ◆◆◆") sys.exit(0)
필자의 티스토리 블로그에서는 실제 포스트의 본문이 시작되는 경우를 위에서와 같이 3개의 케이스를 발견할 수 있었다.
본문이 시작되는 위치는 div 태그에서 class 2종의 3가지 조합 중 하나로 구성되어 있었다. 다시 한번 언급하지만 이 태그도 스킨에 따라 다를 수 있다는 점을 명심해야 한다.
이 코드는 page.find() 메소드에서 해당 태그를 찾는 다면 그 위치를 article 이라는 객체에 리턴하는 3개의 if 문이다.
불필요한 스크립트 및 HTML 속성 제거하기
티스토리 블로그의 포스트를 백업하다 보면 이사 후에는 쓸모없어지는 속성과 스크립트가 꽤 많다. 그런 경우 다음과 같은 방법으로 제거할 수 있다.
# Article에서 모든 java 스크립트 태그 선택 및 제거
if (script_tags := article.find_all('script')):
for script_tag in script_tags:
script_tag.decompose()
# Article에서 adsense가 포함된 div 태그 제거
if (script_tags := article.find_all('div', id='AdsenseM1')):
for script_tag in script_tags:
script_tag.decompose()
# P 태그를 모두 찾아 순차적으로 data-ke-size 속성 제거
p_tags = article.find_all('p')
for p_tag in p_tags:
del p_tag['data-ke-size']
# pre 태그를 찾아 불필요한 attribute 삭제
pre_tags = article.find_all('pre')
for pre_tag in pre_tags:
del pre_tag['id']
del pre_tag['class']
del pre_tag['data-ke-language']
del pre_tag['data-ke-type']
스킨에 따라 다른 속성들이나 태그들이 많이 있는데 불필요한 태그나 속성들을 찾아 차례대로 삭제해주면 된다. 최대한 순수 컨텐츠만 남도록 코드를 만들어주면 좋다.
포스트의 이미지 다운로드
블로그 이사를 위한 티스토리 블로그의 백업 과정에서 난관 중 하나가 첨부된 이미지의 백업과 경로의 변경이다. 먼저 이미지를 다운로드 받아 백업하는 파이썬 코드다.
# 포스트의 컨텐츠에서 이미지 태그를 모두 찾아 다운로드 받고 img 태그 정리 및 URL 경로 변경 코드 시작
img_tags = article.find_all('img')
# 이미지 다운로드
for img_tag in img_tags:
# 이미지 URL
img_url = img_tag['src']
# img tag에 data-filename 이라는 속성이 있으면
if "data-filename" in img_tag.attrs:
fname = img_tag['data-filename']
else: # 없으면
fname = os.path.basename(img_url)
if fname == "img.jpg":
directory_name = os.path.dirname( img_tag['src'])
last_dirname = directory_name.split('/')[-1]
fname = last_dirname
# 이프로그램을 실행하는 현재 경로 아래에 tistory 라는 디렉토리를 생성
os.makedirs (os.getcwd() + "https://img.blogger.pe.kr/tistory/", exist_ok=True)
# 생성한 tistory 디렉토리 아래에 인덱스 번호(포스트의 번호, 즉 웹 경로)로 디렉토리 생성
img_dir = os.path.join(os.getcwd() + "https://img.blogger.pe.kr/tistory/"+str(index))
os.makedirs (img_dir, exist_ok=True)
# 실제 저장할 이미지의 디렉토리와 경로를 조합하여 이미지 파일명 및 경로 완성
img_path = os.path.join(img_dir, fname)
# 이미지 다운로드 (메모리 상에서만 갖고 있음)
img_response = requests.get(img_url)
# 이미지 파일 저장. 파일명에 ? 가 포함되어 있을경우 리눅스에서 파일저장 시 파일명이 '로 묶여 저장되는 경우가 있어 ?를 _로 변경
with open(img_path.replace("?", "_"), 'wb') as img_file:
# 다운로브 받은 이미지를 파일로 쓰기
img_file.write(img_response.content)
img_file_count = img_file_count + 1 # 이미지 다운로드에 성공하면 카운터 1 증가
# 본문에서 img 태그의 이미지파일 웹 경로를 다운로드 받은 tistory 디렉토리의 포스트번호 아래의 파일명으로 src attribute의 값을 변경
img_tag['src'] = "https://img.blogger.pe.kr/tistory/" + str(index) + "/" + fname
# img 태그에서 불필요한 srcset 속성 삭제
del img_tag['srcset']
del img_tag['onerror']
# 포스트의 컨텐츠에서 이미지 태그를 모두 찾아 다운로드 받고 img 태그 정리 및 URL 경로 변경 코드 끝
이미지 파일의 다운로드와 경로 수정이 완료되었으면 이제 본격적으로 본문을 백업할 차례다.
티스토리 블로그 포스트의 본문 백업하기
앞에서 article 이라는 객체에 본문에 해당하는 HTML 코드를 받아두었다. 이 article 객체에서 HTML 태그 객체를 순차적으로 접근하는 메소드는 몇 가지가 있는데 테스트 해본 결과 children 이라는 하위 객체를 순서대로 순회하는 것이 가장 예외 케이스와 오류가 적게 발생했다.
그리고 기본적으로 <p> 태그로 문장들이 저장되어 있다. 그리고 그 하위에 <span> 태그와 <figure>, <pre>, <img> 등등 수 많은 태그 객체들이 본문을 분할하여 저장하고 있다.
하지만 예외도 많다. 본문의 최상단 태그인 <div class=”tt_article_useless_p_margin contents_style”> 태그 다음에 <p> 태그가 오는 것이 일반적인데, 때에 따라선 <div>가 오기도 하고 심한 경우에는 <p>, <span>, <div>가 중복으로 겹쳐오기도 한다. 드물긴 하지만 다른 태그 없이 바로 본문이 오기도 한다. 이런 예외 케이스들이 발견될 때 마다 처리하는 코드를 새로 작성하고 수정하느라 코드 작성에 꽤 긴 시간이 걸렸다. 물론..지금도 완벽하지는 않다.
모든 코드를 설명할 수는 없고 일부만 설명한다. 나머지는 모드 예외처리하는 루틴이다.
# 포스트 본문의 태그를 순차적으로 접근
for tag in article.children:
# 태그가 p 태그 여부 판단함
if tag.name == "p":
# p tag 다음에 figure 태그가 있으면 이미지의 alt 태그 설정함
if sec_tags := tag.find_all('figure'):
for sec_tag in (sec_tags):
# print("- P태그 내부의 figure 찾음")
img_tag = sec_tag.find('img')
alt_text = img_tag.get('alt', '')
# 새롭게 포스트 본문을 저장할 contents에 p 태그 다음에 오는 figure 태그와 img 태그를 재구성하여 저장함
contents = contents + "<figure style='text-align: center;'>\n<img src='" + img_tag['src'].replace("?", "_") + "' alt='" + alt_text + "'>\n"
# figure 태그의 캡션을 caption 변수에 저장
if(figure_tag := sec_tag.find('figcaption')):
caption = figure_tag.text.strip()
# figure 태그의 데이터 모두 추출 후 태그 제거
figure_tag.decompose()
else:
# figure 태그에 하위 figcaption 태그가 없으면 공백으로 처리
caption = ""
# 재구성하는 본문에 figcaption 태그 추가.
contents = contents + "<figcaption>" + caption + "</figcaption>\n</figure>\n"
# 처리한 이미지 개수 카운트 증가
img_tag_count = img_tag_count + 1
이와 같은 방법으로 article 객체의 모든 tag 객체를 순회하며 백업에 필요한 컨텐츠를 contents 객체에 추가한다.
포스트에서 추출한 컨텐츠를 파일에 저장하기
contents 객체에 포스트의 컨텐츠가 모두 저장되면 파일에 써주면 된다.
# 포스트를 저장할 html 파일명 생성
wfilename = os.getcwd() + "https://img.blogger.pe.kr/tistory/" + str(index) + ".html"
# 포스트의 제목 등과 컨텐츠를 파일에 작성
with open(wfilename, "w") as file:
file.write("포스트 제목 : \n" + title.text.strip() + " /" + str(index) + "\n")
file.write("카테고리 : " + category.text.strip() + "\n")
file.write("포스트 작성일자 : " + wdate.text.strip() + "\n")
file.write('워드프레스 Slug : /' + str(index) + "\n")
file.write("-------------\n")
file.write("다운로드 받은 이미지 개수 : " + str(img_file_count) + "\n")
file.write("생성한 IMG 태그 개수 : " + str(img_tag_count) + "\n")
file.write("-------------\n")
file.write(contents)
file.close()
print("다운로드 받은 이미지 개수 : " + str(img_file_count))
print("생성한 IMG 태그 개수 : " + str(img_tag_count))
time.sleep(3)
이 백업 코드를 작성하여 포스트를 백업하고 워드프레스에 새로 포스트를 작성하는데 틈틈히 시간을 투자해 2주 정도 소요되었다.
애초에는 워드프레스의 파이썬 패키지를 사용하고자 했으나 계속 동일한 에러가 발생하였고 원인을 찾을 수 없어 포기했다.
이 노가다 작업을 하면서 파이썬 고수가 나서서 티스토리 블로그의 워드프레스 이사를 위한 파이썬 패키지를 만들어주면 좋겠다는 생각을 잠시나마 했었다.
안녕하세요 우연히 티스토리포럼 -> 티스토리블로그 -> 여기
를 통해서 들어왔네요
궁금한게 있는데 이렇게 해서 글을 옮기면 중복문서로 분류가 안되나요?
당연한 말이겠지만 검색 상위에 있던글도 다 내려오는거겠죠?
티스토리에서 리디렉션을 할 수 가 없으니까요
저는 티스토리에서 구글 블로그로 넘어가는 중입니다. 기존의 글들이 너무 아까워요 휴….
그리고 워드프레스는 댓글에 답을 주시면 이메일이나 그런걸로 알림이 오나요? 궁금하네요
안녕하세요.
글을 모두 옮긴 다음에 티스토리의 글은 일괄로 비공개 처리하시면 됩니다. 다만 URL 주소가 달라지면 완전하게 새로 시작하는 것이라고 생각하셔야 합니다.
저는 애초에 티스토리의 글들이 모두 blogger.pe.kr 이라는 도메인으로 검색엔진에 색인되어 있었기에 검색엔진에 누락은 없습니다.
다만 *.tistory.com 으로 운영을 하셨고 다른 도메인으로 옮긴 후 글을 옮기시는 것이라면 완전히 새로 시작한다고 보셔야 합니다.
그리고 댓글이 달리거나 답글이 달렸을 때 이메일 알림도 설정 가능합니다. 다만 imap이나 smtp가 지원되는 개인 이메일 계정이 있어야 합니다.
방문 감사드립니다~
아 그렇군요 무척 아쉽습니다. 얼마 전에도 워드프레스로 추정되는 블로그에서 뭔가 댓글을 달았었는데
그 사이트를 까먹어서 답변이 있는지 조차 알 수 가 없게 되었네요.
확실히 그런 소통의 부분에선 기존 포털제공 블로그에 비해 좀 아쉬울 수 밖에 없네요.
뭐 장점만 가득인 물건은 없겠죠 ^^
정말 티스토리의 글중 몇몇개는 정말 아까워요 구글하고 네이버 최상단에 떠 있는 글인데 말이죠 ^^;;
감사합니다. 올려주신 댓글을 보고 다음 스마트워크에 설정되어 있던 제 도메인의 메일서버를 연결해 댓글에 대댓글이 달리면 알림 메일이 발송되도록 해봤습니다.
아 메일로 답변이 날아오니 좋네요
제가 몇번 동일한 경험을 해서 참 아쉬웠거던요. 아무래도 검색기반으로 들어가다보니 시간이 지나면 블로그를 까먹게 마련이니까요 TAEHO님 블로그는 구글블로그 읽기목록에 추가해 두었습니다